略
略
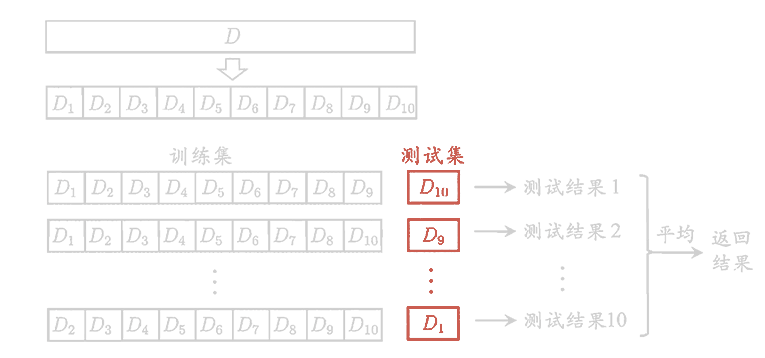
直接将数据集划分为两个互斥地集合,其中一个集合作为训练集,另一个作为测试集。在使用时,一般要采用若干次随机划分,重复进行实验,评估后取平均值作为结果。
假定包含m个样本的数据集D,每次从D中随机挑选一个样本,将其拷贝入D′,重复m次,就得到了包含m个样本的数据集D′。显然,D中的一部分样本会在D′中多次出现,一部分样本不会在D′中出现。该方法在数据集较小,难以有效划分训练集、测试集时很有用,但会引入估计偏差。
MSE(f,y)=mi=1∑m[f(xi)−yi]2
回归任务最常用的性能度量方法。
错误率
E=mi=1∑mⅡ[f(xi)=yi]
精度
Acc=mi=1∑mⅡ[f(xi)=yi]
| 真实情况 |
预测为正例(Positive) |
预测为反例(Negatie) |
| 正例(True) |
真正例(TP) |
伪反例(FN) |
| 反例(False) |
伪正例(FP) |
真反例(TN) |
- m=TP+FP+TN+FN
Accuracy=mTP+TN=TP+FP+TN+FNTP+TN
Specificity=FalseTN=FP+TNTN
Precision=PositiveTP=TP+FPTP
Recall=TrueTP=TP+FNTP
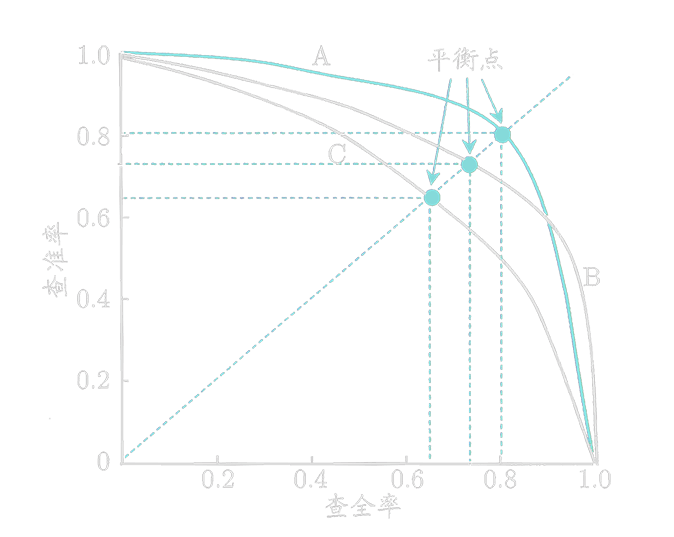
查准率和查全率是一对矛盾的变量,平衡点就是查准率等于查全率时的取值。
F1=21⋅Precision1+21⋅Recall11=Precision+Recall2⋅Precision⋅Recall=2TP+FN+FP2TP
F1是基于查准率和查全率的调和平均数。
Fβ=β2+11⋅Precision1+β2+1β2⋅Recall11=β2⋅Precision+Recall(1+β2)⋅Precision⋅Recall
Fβ是基于查准率和查全率的加权调和平均数,当β=1时,即为F1。
ROC(Receiver Operating Characteristic,受试者工作特征)曲线纵轴为“真正例率(TPR,True Positive Rate)”,横轴是“假正例率(FPR,False Positive Rate)”。
- TPR=TrueTP=TP+FNTP
- FPR=FalseFP=FP+TNFP
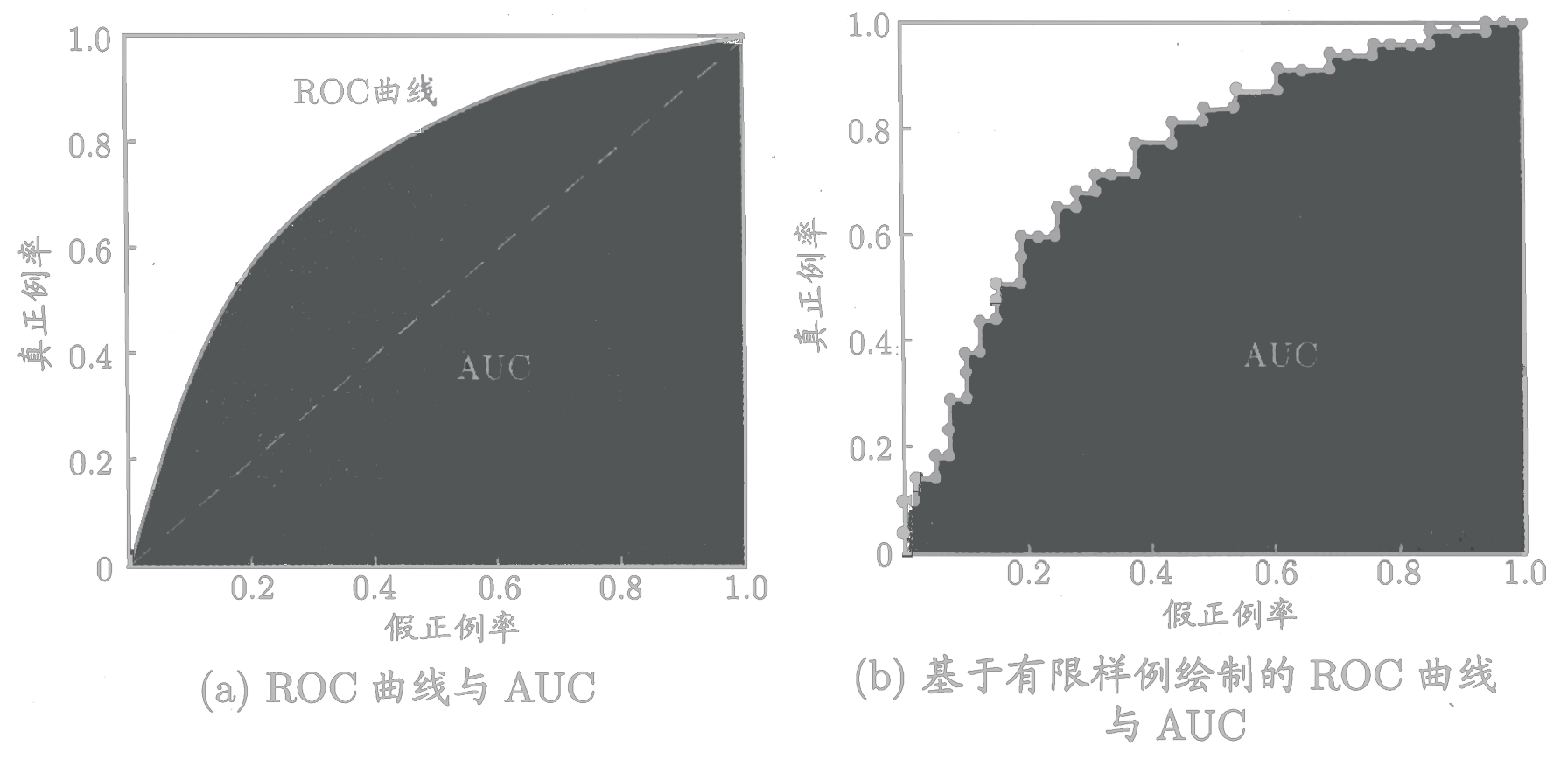
“AUC(Area Under Curve)”为ROC曲线所覆盖的区域面积。AUC越大,分类器分类效果越好。
| AUC |
效果 |
| 1 |
完美分类器 |
| (0.5,1) |
优于随机猜测 |
| 0.5 |
等价于随机猜测 |
| (0,0.5) |
差于随机猜测 |
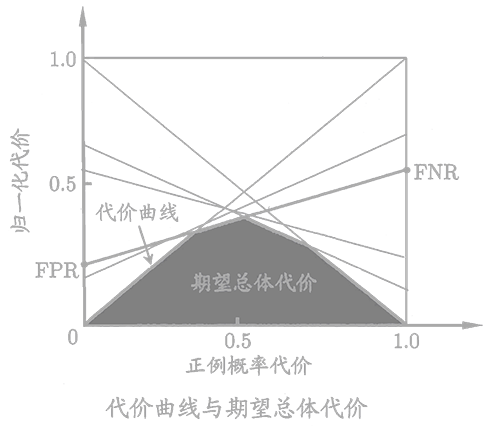
在非均等代价下ROC曲线不能反映出学习器的期望总体代价。
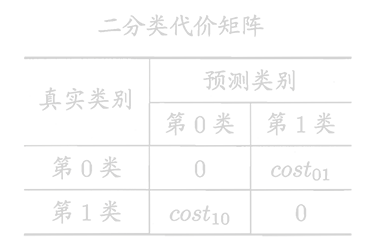
E=mxi∈D+∑Ⅱ(f(xi)=yi)cost01+xi∈D−∑Ⅱ(f(xi)=yi)cost10
- D+:实例集D的正例子集。
- D−:实例集D的反例子集。
横轴为“正概率代价”,纵轴为“归一化代价”。
P(+)cost=p⋅cost01+(1−p)⋅cost10p⋅cost01
costnorm=p⋅cost01+(1−p)⋅cost10FNR⋅p⋅cost01+FPR⋅(1−p)⋅cost10
- FNR=TrueFN
- FPR=FalseFP
我们希望比较的是泛化性能,然而通过实验评估方法我们获得的是测试集上的性能,两者的对比结果未必相同。
| 比较算法数量 |
检验名称 |
说明 |
| 2 |
交叉验证t检验 |
|
| 2 |
McNemar检验 |
|
| * |
Friendman检验 |
|
| * |
Nemenyi后续检验 |
|
偏差
biasi=f(xi)−yi
方差
ε2=mi=1∑mbiasi2
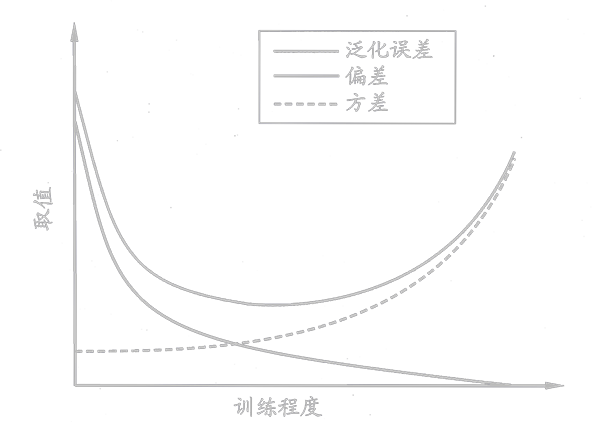
偏差方差窘境(Bias-Variance Dilemma)
一般来说,偏差与方差是有冲突的,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率。