机器学习:聚类
基本概念
将数据分组成簇,使得簇内相似度尽可能高,簇间相似度尽可能低的无监督学习方法。
常见聚类算法
- Partition-based methods
- K-Means
- Density-based methods
- DBSCAN
- OPTICS(Ordering points to identify the clustering structure)
- Hierarchical methods
- Ward(凝聚法层次聚类)
- BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)
- Chameleon
- Agglomerative
- Grid-based methods
- STING(STatistical INformation Grid)
- WAVE-CLUSTER
- CLIQUE(CLustering In QUEst)
- Model-based methods
- GMM(Gaussian Mixture Models)
- SOM(Self Organized Maps)
- Fuzzy-based methods
- FCM
- Other methods
- SLC(Sequential Leader Clustering)
- Spectral
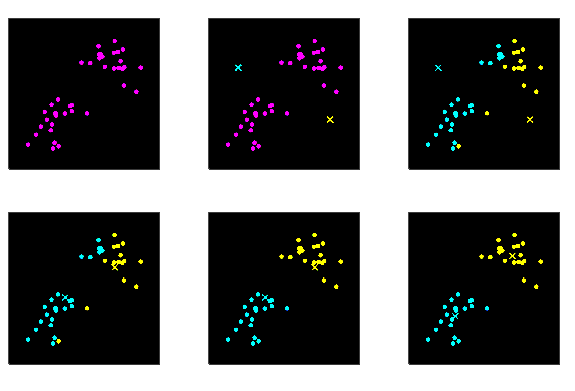
K-Means
特点
优点
- 收敛速度快(5步左右)
缺点
- 要求用户必须事先给出要生成的簇的数
- 对噪音和异常点比较的敏感
- 非凸的数据集比较难收敛
- 最终可能只是局部最优解
原理
对于给定的样本集,按照样本之间的距离大小,将样本集划分为个簇。让簇内的点尽量紧密的连在一起(尽可能小),而让簇间的距离尽量的大。
- :样本被划分为个簇
- :簇划分为
- :簇的均值向量,
流程
- 输入:、
- Step1:从数据集中随机选择个样本作为初始的质心向量
- Step2:把每个样本分配到距离它最近的质心形成的簇
- 选出距离最近的作为的簇,
- 将加入到簇,
- Step3:重新计算均值向量
- 重复Step2、Step3直到满足要求
- 输出:
迭代过程
Ward Hierarchical Clustering
思想
凝聚的层次聚类采用自底向上策略,首先将每个样本作为一个簇,然后合并这些原子簇形成越来越大的簇,以减少簇的数目,直到所有的样本都在一个簇中,或某个终结条件被满足。
距离判定
| 单链接(Single Linkage) | 最小距离 | 两个簇的最近样本决定 |
| 全链接(Complete Linkage) | 最大距离 | 两个簇的最远样本决定 |
| 均链接(Average Linkage) | 平均距离 | 两个簇所有样本共同决定 |
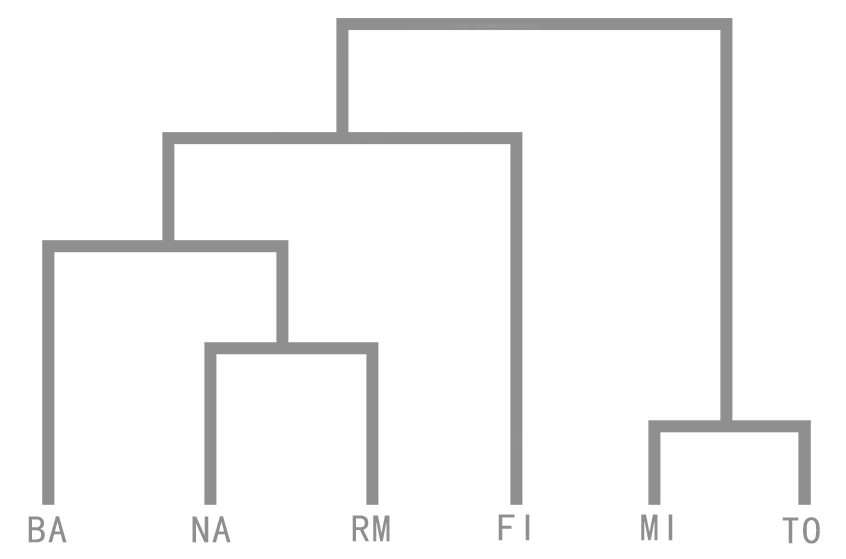
Example
| BA | FI | MI | NA | RM | TO | |
|---|---|---|---|---|---|---|
| BA | 0 | 662 | 877 | 255 | 412 | 996 |
| FI | 662 | 0 | 295 | 468 | 268 | 400 |
| MI | 877 | 295 | 0 | 754 | 564 | 138 |
| NA | 255 | 468 | 754 | 0 | 219 | 869 |
| RM | 412 | 268 | 564 | 219 | 0 | 669 |
| TO | 996 | 400 | 138 | 869 | 669 | 0 |
使用Single Linkage进行聚合
Step1:聚合MI和TO
| BA | FI | MI/TO | NA | RM | |
|---|---|---|---|---|---|
| BA | 0 | 662 | 877 | 255 | 412 |
| FI | 662 | 0 | 295 | 468 | 268 |
| MI/TO | 877 | 295 | 0 | 754 | 564 |
| NA | 255 | 468 | 754 | 0 | 219 |
| RM | 412 | 268 | 564 | 219 | 0 |
Step2:聚合NA和RM
| BA | FI | MI/TO | NA/RM | |
|---|---|---|---|---|
| BA | 0 | 662 | 877 | 255 |
| FI | 662 | 0 | 295 | 268 |
| MI/TO | 877 | 295 | 0 | 564 |
| NA/RM | 255 | 268 | 564 | 0 |
Step3:聚合BA和NA/RM
| BA/NA/RM | FI | MI/TO | |
|---|---|---|---|
| BA/NA/RM | 0 | 268 | 564 |
| FI | 268 | 0 | 295 |
| MI/TO | 564 | 295 | 0 |
Step4:聚合BA/NA/RM和FI
| BA/NA/RM/FI | MI/TO | |
|---|---|---|
| BA/NA/RM/FI | 0 | 295 |
| MI/TO | 295 | 0 |
DBSCAN
待补充
GMM
待补充